
כמדעני נתונים, אנחנו תמיד שואפים שהמודלים שלנו יהיו מדוייקים יותר – שיספקו תחזיות טובות יותר או תגובות טובות יותר לשאלות (לדוגמה במקרה של מודלי שפה).
כמקבלי החלטות עסקיות אנחנו גם תמיד זוכרים שדיוק דורש יותר משאבים (לדוגמה כסף, מחקר, כ"א, דאטה מטויב, וכוח מחשוב).
יש איזון בין דיוק לבין עלות, והפוסט שלפניכם דן באיזון הזה.
למה השאלה הזו רלוונטית לכל עסק בכל גודל
בעולם של היום AI זמין בכל מקום ולכל אחד (לדוגמה, ChatGPT), ולכן השאלה של "האם כדאי לי להשקיע ולהשתמש במודל טוב יותר" רלוונטית לכל עסק- החל מעסקים קטנים ועד ענקיות טק.
בעת כתיבת שורות אלו יש מגוון רחב של פתרונות AI. אם נתמקד לרגע במודלי שפה, וספציפית ב-ChatGPT, אז חלק מהפתרונות חינמיים (כמו ChatGPT3.5) וחלקם בתשלום (כמו ChatGPT4, שכרגע עולה $20 בחודש). יש גם מודלים אחרים בתשלום למטרות ספציפיות ובפיתוח של חברות אחרות.
כתלות במשימה שבפתח, מקבלי החלטות צריכים להחליט אם מודל משופר או מדויק יותר שווה את ההשקעה. האמת שההשוואה הזו לא כל כך פשוטה כשמדובר במודלי שפה. לדוגמה, איך הייתם משווים בין שני השירים הללו שנכתבו על ידי ChatGPT במענה לבקשה a short poem about a flower, up to 10 words:
ChatGPT3.5: “Petals dance, whispering secrets, the flower's silent poetry unfolds.”
ChatGPT4: “A flower blooms, with grace and beauty. A gift of nature, a joy to see.”
כנראה ששניהם בסדר, ושהיתר זה העדפה אישית. לפעמים האיכות נקבעת על ידי הפרומפט (תוכן הבקשה) יותר מאשר על ידי המודל.
עסקים שמפתחים מודלים לשימושים פנימיים נתקלים גם בדילמות מורכבות יותר, שבהן הם צריכים לקבוע האם המודל מדויק דיו. שיפורים של המודל עולים כסף, כגון דאטה נוסף מתויג (שעות עבודה של תיוג), התממשקות למקורות נתונים נוספים (מחיר של קריאות לנתונים נוספים), וכמובן השקעות בתשתיות אימון המודלים (זמן חישוב).
אבל בואו ונראה דוגמה מוצקה.
דוגמה עם מודל סיווג (קלאסיפיקציה)
מודלים לסיווג הם מודלים שמסווגים תצפית לקטגוריה, לדוגמה:
-
האם ליד (lead) מסוים יהפוך ללקוח משלם?
-
האם לקוח קיים ישאר נאמן או ינטוש?
-
האם המטופל יגיע לתור שנקבע לו עם הרופא?
-
האם העסקה הזו היא לגיטימית או הונאה?
על שאלות כאלו ניתן לענות באמצעות מודל חיזוי, בהנחה שיש מספיק נתונים לאמן את המודל ולהריץ אותו. אבל יש איזון בין עלות השימוש במודל לבין התועלת ממנו, ובאיזון הזה נתמקד כעת.
נניח שפיתחנו מודל שמחזיר לנו את ההסתברות לכך שליד מסוים יהפוך להיות לקוח משלם. המודל הזה משתמש בגיל, מגדר, ובמשך הזמן שהלקוח היה באתר האינטרנט שלנו. נניח שגם פיתחנו מודל משופר שמשתמש גם בנתון סוציואקונומי של הליד (באמצעות שירות בתשלום שעושה שימוש בכתובת IP של הלקוח כדי לחלץ נתון סוציואקונומי).
המודל המשופר טוב יותר מהמודל המקורי. שני המודלים פותחו ועובדים. אבל המודל המקורי לא עולה לנו כסף (כמעט, בעצם יש עלויות זניחות של תשתיות). המודל המשופר עולה $1 לכל הרצה (עבור השירות שמחלץ את הנתון הסוציואקונומי).
בסיפור שלנו, אם ליד יהפוך ללקוח משלם בסבירות גבוהה, אז אנחנו רוצים לשלוח לו מתנה, כדי להצליח לסגור את העסקה. לעומת זאת, ליד שהסבירות שלו להפוך ללקוח משלם היא נמוכה מאוד, אז אין סיכוי להפוך אותו ללקוח משלם, גם אם נשלח לו מתנה. וכאמור- זו רק דוגמה להמחשה.
אם המודל שלנו "רגיש מדי" אז הוא יזהה יותר מדי לידים כלקוחות פוטנציאליים ואנחנו נידרש לשלוח הרבה מתנות (ונוציא הרבה כסף בדרך). לחילופין, אם המודל שלנו גס מדי, אז לא נצליח לזהות לידים טובים ולא נסגור מספיק עסקאות.
אנחנו יכולים לנתח את הכדאיות של שני המודלים באמצעות תרשים שנקרא ROC, שמציג את הרגישות (היכולת לזהות ליד שהופך ללקוח) לעומת הסגוליות (או "ספציפיות", קרי, היכולת לזהות ליד שלא יהפוך ללקוח). בתרשים שלפניכם אנחנו מציגים את הרגישות (בציר y) ואת הסגוליות (בציר x, למעשה זה "אחד פחות הסגוליות"), עבור שני המודלים (המקורי והמשופר).
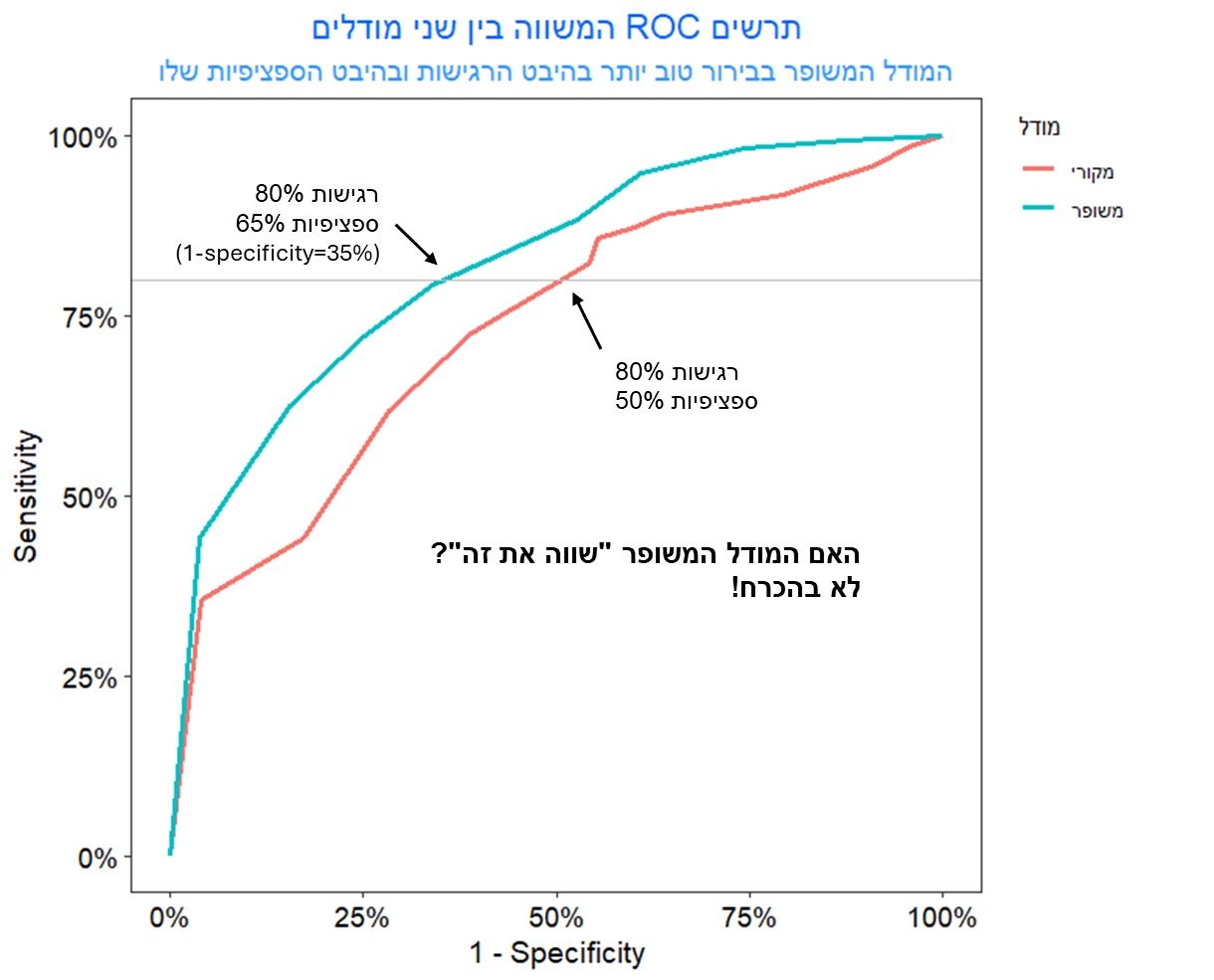
איפה האיזון?
האם המודל המשופר "שווה את זה"? תלוי בפרטים (כמה לידים מגיעים בחודש, מה העלות של המתנה שאנחנו שולחים, וכו').
נניח שיש לנו 1000 לידים בחודש, וששיעור הלידים שיכולים להפוך לעסקאות הוא 10% (כלומר 100 לידים יהפכו ללקוחות משלמים, אם נשלח להם מתנה). נניח לרגע שאנחנו רוצים לעמוד על רגישות של 80% כלומר להצליח להשיג לפחות 80 לקוחות משלמים (80% מתוך 10% מתוך 1000 לידים).
במודל המקורי נשלח 450 מתנות ל"סתם לידים" כי הסגוליות שלנו עומדת על 50%, מתוך 900 לידים שלא יהפכו להיות לקוחות גם אם יקבלו מתנה.
במודל המשופר נשלח 315 מתנות ל"סתם לידים" כי הסגוליות שלנו עומדת על 65% (שגיאה של 35% מתוך 900).
כלומר ההבדל בין המודל המקורי למודל המשופר הוא חיסכון של 135 ��תנות מיותרות (במודל המשופר חסכנו). אפשר אגב היה להסתכל במקום על חיסכון על רווח (אם היינו מחזיקים תקציב נתון, ובודקים איך הרגישות הגבוהה יותר של המודל המשופר עוזרת לנו לזהות יותר לקוחות).
במודל המשופר עלות הרצת המודל היא $1000 יותר מאשר במודל המקורי, ולכן נקודת האיזון היא עלות של $7.41 למתנה (135 מתנות מיותרות * $7.41 ליחידה = $1000). אם עלות המתנה יקרה יותר, אז עדיף להשתמש במודל המשופר וכך לקנות פחות מתנות מיותרות. אם העלות של המתנה זולה יותר מ-$7.41 אז עדיף לעבוד עם המודל המקורי.
איך להחליט?
הכלים שתיארתי לעיל הם כלים קלאסיים של מדעי הנתונים, אבל מה אם אין לכם מדען נתונים בחברה? אז תיצרו איתנו קשר!
אבל עכשיו ברצינות – הנה כמה נקודות שאפשר לרוץ איתן גם מבלי להיות מדען נתונים. שאלו את עצמכם את השאלות הבאות:
-
מהם המודלים שיכולים לסייע לי? מה זמין בשוק?
-
מה רמת הדיוק של כל אחד מהמודלים?
-
מה העלות של כל אחד מהמודלים? האם זו עלות "כללית חודשית" או מודל "לכל שאילתא"?
-
מה הערך שאתם מקבלים מכל מודל? (יותר פדיון? חיסכון בהוצאה?)
-
מה העלות של "לא להשתמש במודל בכלל"?
אם חלק מהתשובות לשאלות הללו לא זמינות לכם, ניתן להעריך אותם או אפילו להתנסות עם המודלים השונים במודל "freemium" או בתשלום למשך זמן מוגבל. כך תוכלו להבין איזה ערך אתם מקבלים מהם, ולקבל אינטואיציה על כדאיות השימוש במודלים.
סיכום
שיפור רמת הדיוק של מודלי AI עשויה להיות מטרת העל לחוקרים, אבל מנקודת מבט עסקית, זו תמיד שאלה של עלות-תועלת, כמו כל שאלה עסקית אחרת. עם עקרונות בחינה מבוססים, ושימוש ב-KPIs מקובלים כמו רגישות וסגוליות, עלויות, וכלי אופטימיזציה, אנחנו עשויים להגיע למסקנות מפתיעות.
כמו תמיד, אם מצאתם את הפוסט מעניין, ספרו לנו! אם אתם מעוניינים לשמוע עוד או נתקלים בדילמות כאלו אצלכם – אתם מוזמנים לפנות אלינו.